Football Match Prediction with Web Scraping and Python
This project automates the collection and analysis of football match data through web scraping and statistical processing using Python. Its goal is to identify the most predictable matches based on metrics such as goal differences, recent performance, and odds variation. The entire workflow runs with a single command and produces structured results in JSON files, along with a prompt ready for ChatGPT if additional analysis is desired. This work was developed as a personal and experimental exercise, intended for learning and technical curiosity rather than betting or profit-making purposes.
Tools used in this project:
- Language: Python
- Libraries: Selenium
- Design pattern: Simple
How does the project work?
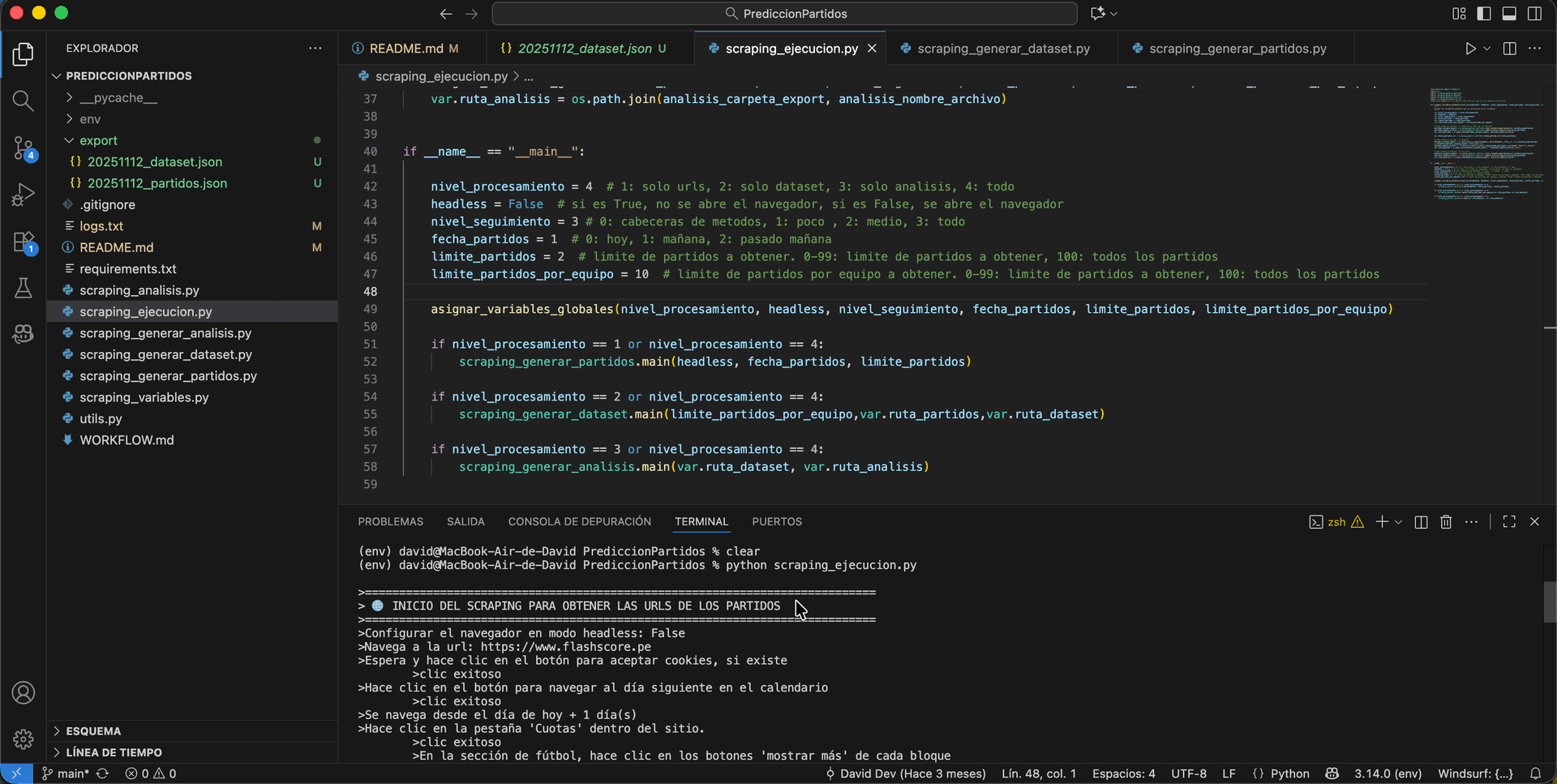
The entire system is designed to run fully automatically by executing the command: python scraping_ejecucion.py. Broadly speaking, this main script contains global variables that control the behavior of the execution: analysis depth, logging, fixed or total number of matches, review date, among other parameters. The first step is a scraping process directed at a football results website. It queries a specific date, expands all available matches according to the requested amount, and retrieves the links for each game. Finally, all this information is stored in a JSON file.
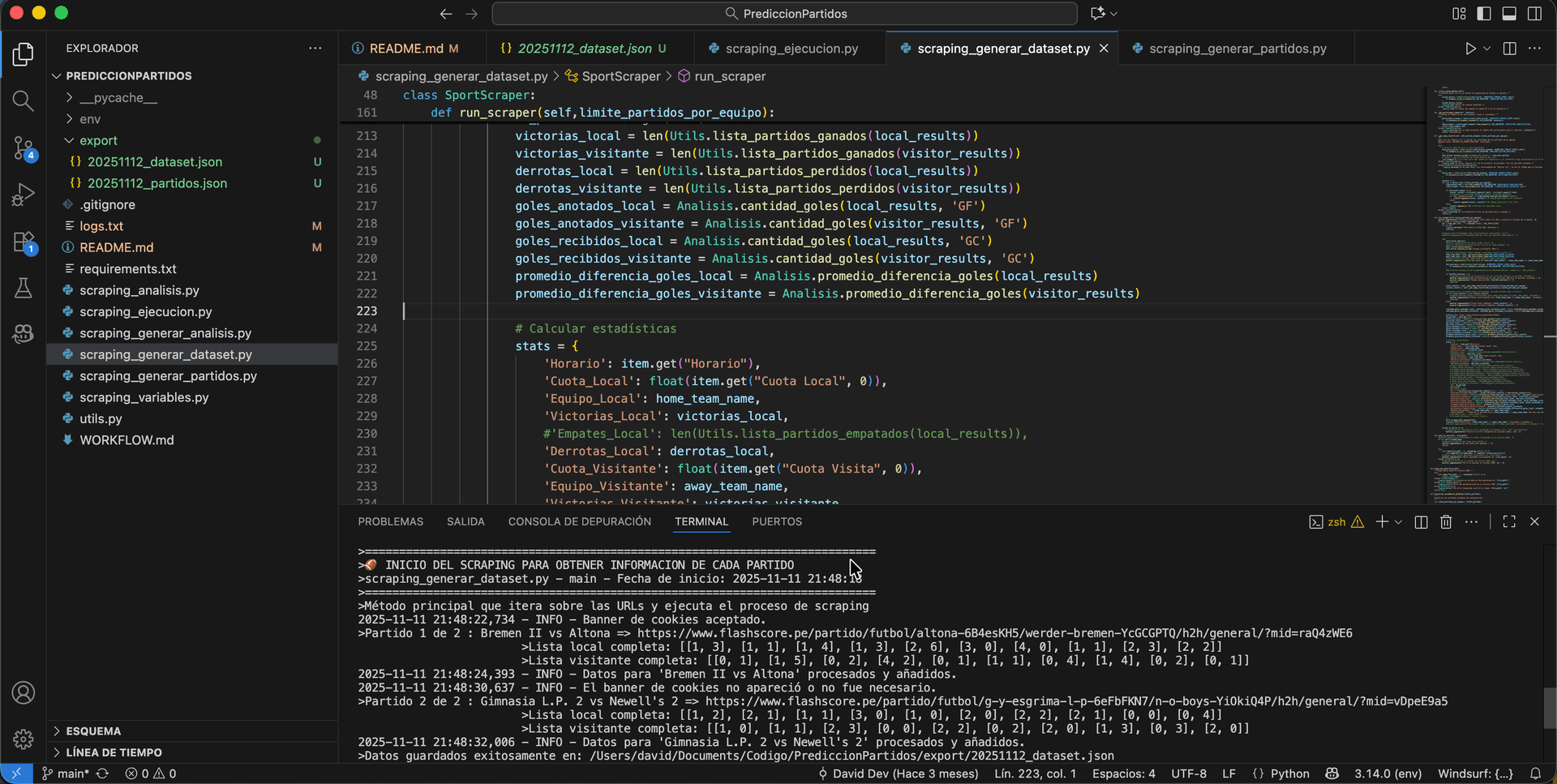
Next, another module runs and visits each of the previously collected match pages to extract the historical data of both teams. With that data, the script organizes and calculates various statistical criteria for further evaluation, such as goal differences, average goals scored and conceded, win/loss balance, odds variation, recent performance, among other indicators. Once these metrics are computed, a new JSON file is generated containing the prepared data for the next stage of the process.
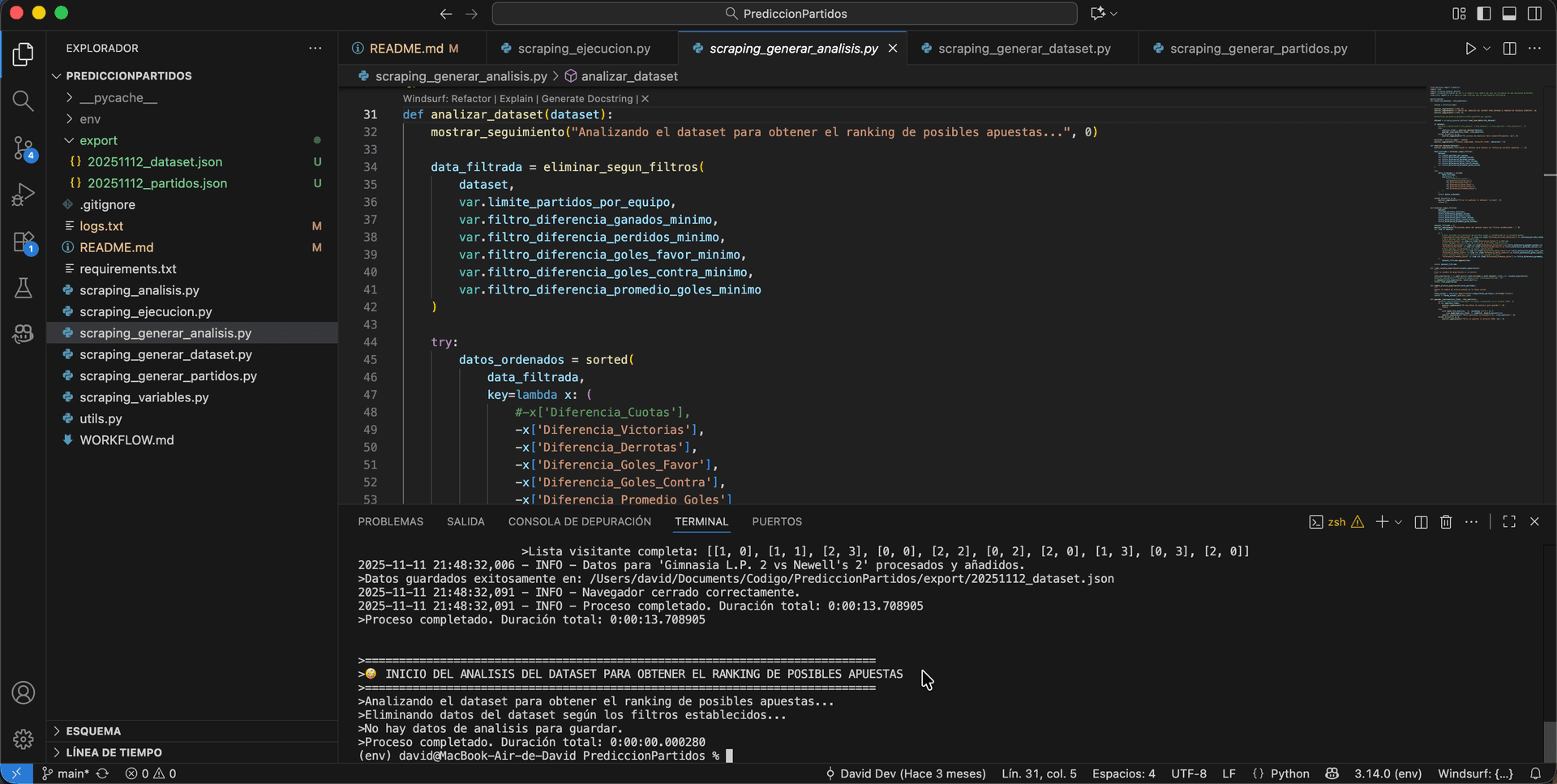
During a full execution —especially over a weekend— it is possible to find more than 1,000 upcoming matches. At this stage, the system applies filters, calculations, and sorting operations based on the previously defined criteria, ultimately generating a list —for instance, a configurable top 10— of matches with the most predictable or seemingly unbalanced outcomes.
Finally, the top matches are reviewed manually, taking into account external factors such as recent news, team conditions, and tournament context. Using that information, a prompt is generated to query ChatGPT and decide whether it’s worth placing a bet or not. After a short experimentation period, these were the results obtained.
My humble conclusion is that it’s not profitable under the current configuration. As Warren Buffett once said: “the short term is unpredictable.” Even if you find a match in the fifth division of Kosovo —where the leader faces the bottom team— the risk is usually greater than the reward. That said, the algorithm could be significantly improved by focusing on more concrete leagues where richer statistics are available. For example, by specializing in the German second division and assigning each team a dynamically updated weighted score, adding or subtracting points based on transfers, injuries, debuts, streaks, or other contextual factors. In summary: say no to gambling addiction.